机器学习笔记(一)基础知识
什么是机器学习?
- 机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。
- 在计算机系统中,“经验”通常以数据的形式存在。因此机器学习研究的主要内容是关于在计算机上从数据中产生“模型”的算法,即
学习算法(learning algorithm)。有了学习算法,我们将经验数据提供给它,它就能基于这些数据产生“模型”。模型能给我们提供相应的判断。 - 可以说机器学习是研究关于“学习算法”的学问。
Mitchell给出了一个更加形式化的定义:假设用$P$来评估计算机程序在某任务类$T$上的性能。若一个程序通过利用经验$E$在$T$中任务上获得了
性能改善,则我们说关于$T$和$P$,该程序对$E$进行了学习。
模型and模式?
- “模型”泛指从数据中学得的结果。有文献用“模型”指全局性结果(例如一棵决策树),而用“模式”指局部结果(如一条规则)。
基本术语
-
数据集(data set)一组关于对象的记录的集合称为一个
数据集,其中记录表示一个事件或一个对象的描述,称为示例(instance)或样本(sample)。反映事件或对象在某方面的表现或性质的事项称为特征(feature)或属性(attribute),其中的取值称为属性值(attribute value)。属性扩张成的空间称为样本空间或输入空间。若以特征为坐标轴,则$n$个特征即张成一个$n$维空间,其中每个样本均可在其中找到一个坐标与之对应,此时一个样本也可称为一个特征向量(feature vector)。有时一个样本可代表整个数据集。因为它可看作是对样本空间做的一个采样。
-
学习过程从数据集中学到模型的过程称为
学习或训练过程。这一过程所用到的数据集称为训练集,其中的样本称为训练样本。学习得到的模型对应于数据中存在的某种潜在规律。这种潜在规律称为真相(ground-truth)。学习的过程就是为了找出或无限逼近真相。所以模型有时被称为学习器。可以看作学习算法在给定数据和参数空间上的实例。学习算法通常有参数设置,不同的参数设置和不同的训练集将产生不同的结果。
-
标记(label)为了建立关于
预测(prediction)的模型,除了示例数据,我们还需获取样本的结果信息。这样的结果信息称为标记(label);而拥有标记的示例,称为样例(example)。我们可以用$(\pmb{x}_i,y_i)$来表示第$i$个样例。其中$\pmb{x}_i$表示示例,$y_i$表示其对应的标记。所有标记$y_i$构成的集合称标记空间(label space)或输出空间。 -
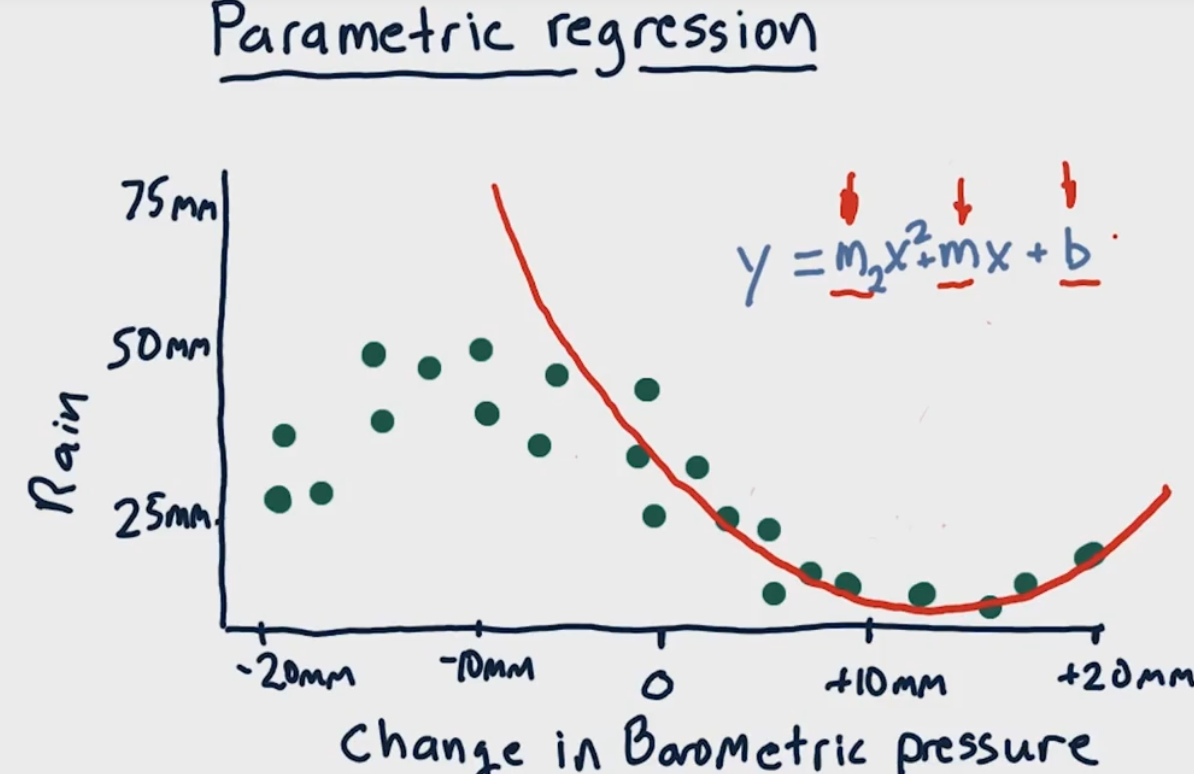
分类(classification)or回归(regression)若我们将要预测的值是离散的,则称此类学习任务为
分类;若预测的值连续,则称回归。而根据类别个数,分类任务又分为二分类(binary classification)和多分类(multi-class classification)。在二分类任务中,通常一个称为正类(positive class),一个称为负类(negative class)。通常预测任务的主要内容是通过对训练集的学习来建立一个从输入空间$\mathcal{X}$到输出空间$\mathcal{Y}$的映射。对二分类任务,通常令$\mathcal{Y}={-1,+1}$或${0,1}$;对多分类任务,$|\mathcal{Y}|>2$;对回归任务,$\mathcal{Y}=\mathbb{R}$。 -
测试(testing)在学到模型之后,还应对其进行性能评估。这一过程称为
测试。待预测的样本称为测试样本(testing sample)。 -
聚类(clustering)将训练集中的样本划分为若干组,每一组称为一个
簇(cluster)。这些自动形成的簇可能对应一些潜在的概念划分。应用此学习过程可以帮助我们挖掘一些数据内在的规律。而这种学习过程不要求训练集拥有标记信息,否则标记信息可能会直接影响簇划分的结果。 -
监督学习(supervised learning)和无监督学习(unsupervised learning)根据训练集是否拥有标记信息,我们可将学习任务划分为两大类:
监督学习和无监督学习。上文提及的分类和回归是前者的代表,而聚类则是后者的代表。 -
泛化(generalization)我们应该明白这一点,机器学习的目标应该是使模型能更好地适用于新样本而非训练数据。因此我们应该加强学得模型的适应能力,即
泛化能力。我们通常假设样本服从一个未知分布且相互独立,即
独立同分布(i.i.d.)。一般而言,训练样本越多,样本空间越大,则我们能得到的信息越多,越有可能通过学习得到泛化能力强的模型。